
Databricks-Certified-Professional-Data-Engineer Exam Question 81
You are currently asked to work on building a data pipeline, you have noticed that you are currently working with a data source that has a lot of data quality issues and you need to monitor data quality and enforce it as part of the data ingestion process, which of the following tools can be used to address this problem?
Databricks-Certified-Professional-Data-Engineer Exam Question 82
Below sample input data contains two columns, one cartId also known as session id, and the second column is called items, every time a customer makes a change to the cart this is stored as an array in the table, the Marketing team asked you to create a unique list of item's that were ever added to the cart by each customer, fill in blanks by choosing the appropriate array function so the query produces below expected result as shown below.
Schema: cartId INT, items Array<INT>
Sample Data
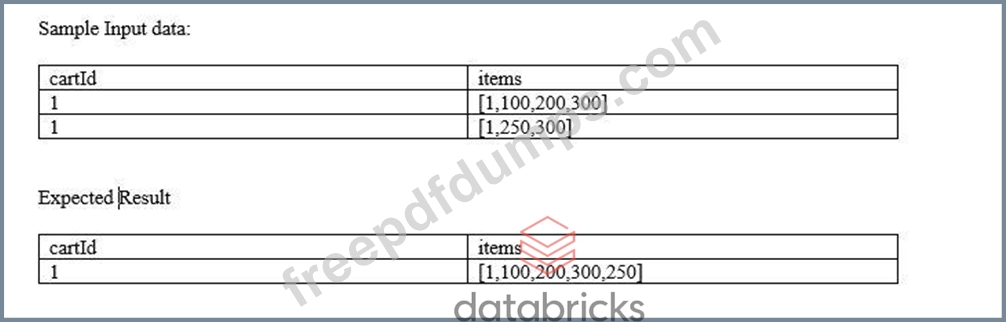
1.SELECT cartId, ___ (___(items)) as items
2.FROM carts GROUP BY cartId
Expected result:
cartId items
1 [1,100,200,300,250]
Schema: cartId INT, items Array<INT>
Sample Data
1.SELECT cartId, ___ (___(items)) as items
2.FROM carts GROUP BY cartId
Expected result:
cartId items
1 [1,100,200,300,250]

Databricks-Certified-Professional-Data-Engineer Exam Question 83
Which of the following techniques structured streaming uses to ensure recovery of failures during stream processing?
Databricks-Certified-Professional-Data-Engineer Exam Question 84
How VACCUM and OPTIMIZE commands can be used to manage the DELTA lake?
Databricks-Certified-Professional-Data-Engineer Exam Question 85
You have written a notebook to generate a summary data set for reporting, Notebook was scheduled using the job cluster, but you realized it takes 8 minutes to start the cluster, what feature can be used to start the cluster in a timely fashion so your job can run immediatley?
