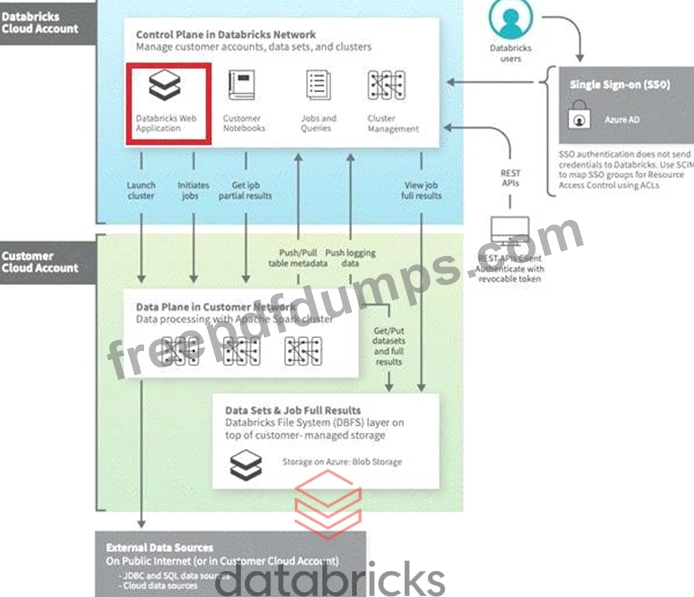
Which of the following are stored in the control pane of Databricks Architecture?
Correct Answer: D
Explanation The answer is Databricks Web Application Azure Databricks architecture overview - Azure Databricks | Microsoft Docs Databricks operates most of its services out of a control plane and a data plane, please note serverless features like SQL Endpoint and DLT compute use shared compute in Control pane. Control Plane: Stored in Databricks Cloud Account * The control plane includes the backend services that Databricks manages in its own Azure account. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest. Data Plane: Stored in Customer Cloud Account * The data plane is managed by your Azure account and is where your data resides. This is also where data is processed. You can use Azure Databricks connectors so that your clusters can connect to external data sources outside of your Azure account to ingest data or for storage. Timeline Description automatically generated Bottom of Form Top of Form
At the end of the inventory process, a file gets uploaded to the cloud object storage, you are asked to build a process to ingest data which of the following method can be used to ingest the data in-crementally, schema of the file is expected to change overtime ingestion process should be able to handle these changes automatically. Below is the auto loader to command to load the data, fill in the blanks for successful execution of below code. 1.spark.readStream 2..format("cloudfiles") 3..option("_______","csv) 4..option("_______", 'dbfs:/location/checkpoint/') 5..load(data_source) 6..writeStream 7..option("_______",' dbfs:/location/checkpoint/') 8..option("_______", "true") 9..table(table_name))
Correct Answer: C
Explanation The answer is cloudfiles.format, cloudfiles.schemalocation, checkpointlocation, mergeSchema. Here is the end to end syntax of streaming ELT, below link contains complete options Auto Loader options | Databricks on AWS 1.spark.readStream 2..format("cloudfiles") # Returns a stream data source, reads data as it arrives based on the trigger. 3..option("cloudfiles.format","csv") # Format of the incoming files 4..option("cloudfiles.schemalocation", "dbfs:/location/checkpoint/") The location to store the inferred schema and subsequent changes 5..load(data_source) 6..writeStream 7..option("checkpointlocation","dbfs:/location/checkpoint/") # The location of the stream's checkpoint 8..option("mergeSchema", "true") # Infer the schema across multiple files and to merge the schema of each file. Enabled by default for Auto Loader when inferring the schema. 9..table(table_name)) # target table
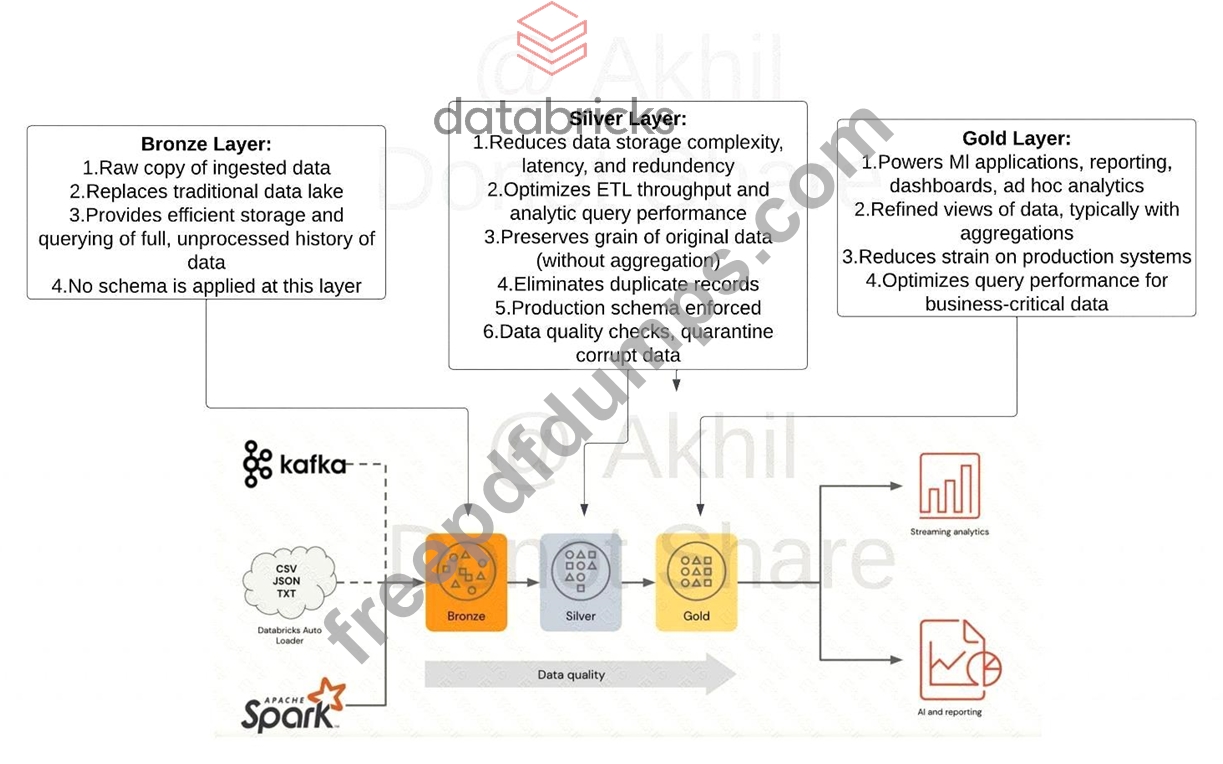
What is the purpose of the bronze layer in a Multi-hop architecture?
Correct Answer: E
Explanation The answer is Provides efficient storage and querying of full unprocessed history of data Medallion Architecture - Databricks Bronze Layer: 1.Raw copy of ingested data 2.Replaces traditional data lake 3.Provides efficient storage and querying of full, unprocessed history of data 4.No schema is applied at this layer Exam focus: Please review the below image and understand the role of each layer(bronze, silver, gold) in medallion architecture, you will see varying questions targeting each layer and its purpose. Sorry I had to add the watermark some people in Udemy are copying my content.
Which of the following is a true statement about the global temporary view?
Correct Answer: A
Explanation The answer is, A global temporary view is available only on the cluster it was created. Two types of temporary views can be created Session scoped and Global *A session scoped temporary view is only available with a spark session, so another notebook in the same cluster can not access it. if a notebook is detached and re attached the temporary view is lost. *A global temporary view is available to all the notebooks in the cluster, if a cluster restarts global temporary view is lost.
Which of the following Auto loader structured streaming commands successfully performs a hop from the landing area into Bronze?
Correct Answer: B
Explanation The answer is 1.spark\ 2..readStream\ 3..format("cloudFiles") \# use Auto loader 4..option("cloudFiles.format","csv") \ # csv format files 5..option("cloudFiles.schemaLocation", checkpoint_directory)\ 6..load('landing')\ 7..writeStream.option("checkpointLocation", checkpoint_directory)\ 8..table(raw) Note: if you chose the below option which is incorrect because it does not have readStream 1.spark.read.format("cloudFiles") 2..option("cloudFiles.format","csv") 3.... 4... 5... Exam focus: Please review the below image and understand the role of each layer(bronze, silver, gold) in medallion architecture, you will see varying questions targeting each layer and its purpose. Sorry I had to add the watermark some people in Udemy are copying my content. A diagram of a house Description automatically generated with low confidence