Databricks-Certified-Professional-Data-Engineer Exam Question 111
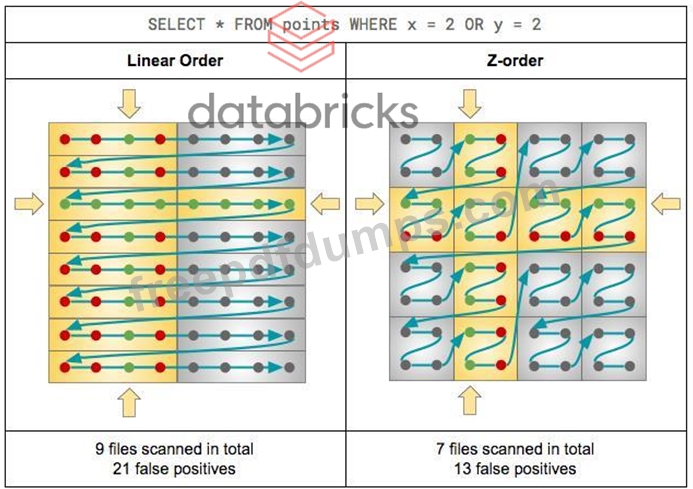
You are still noticing slowness in query after performing optimize which helped you to resolve the small files problem, the column(transactionId) you are using to filter the data has high cardinality and auto incrementing number. Which delta optimization can you enable to filter data effectively based on this column?
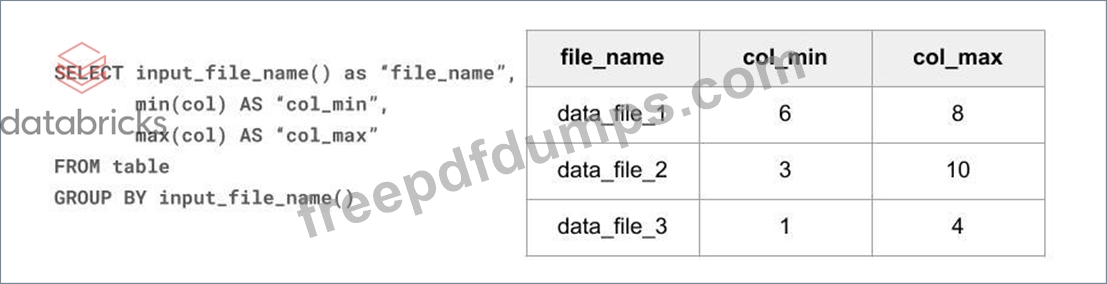
Databricks-Certified-Professional-Data-Engineer Exam Question 112
A data engineer needs to dynamically create a table name string using three Python varia-bles: region, store,
and year. An example of a table name is below when region = "nyc", store = "100", and year = "2021":
nyc100_sales_2021
Which of the following commands should the data engineer use to construct the table name in Py-thon?
and year. An example of a table name is below when region = "nyc", store = "100", and year = "2021":
nyc100_sales_2021
Which of the following commands should the data engineer use to construct the table name in Py-thon?
Databricks-Certified-Professional-Data-Engineer Exam Question 113
When scheduling Structured Streaming jobs for production, which configuration automatically recovers from query failures and keeps costs low?
Databricks-Certified-Professional-Data-Engineer Exam Question 114
A data pipeline uses Structured Streaming to ingest data from kafka to Delta Lake. Data is being stored in a bronze table, and includes the Kafka_generated timesamp, key, and value. Three months after the pipeline is deployed the data engineering team has noticed some latency issued during certain times of the day.
A senior data engineer updates the Delta Table's schema and ingestion logic to include the current timestamp (as recoded by Apache Spark) as well the Kafka topic and partition. The team plans to use the additional metadata fields to diagnose the transient processing delays:
Which limitation will the team face while diagnosing this problem?
A senior data engineer updates the Delta Table's schema and ingestion logic to include the current timestamp (as recoded by Apache Spark) as well the Kafka topic and partition. The team plans to use the additional metadata fields to diagnose the transient processing delays:
Which limitation will the team face while diagnosing this problem?
Databricks-Certified-Professional-Data-Engineer Exam Question 115
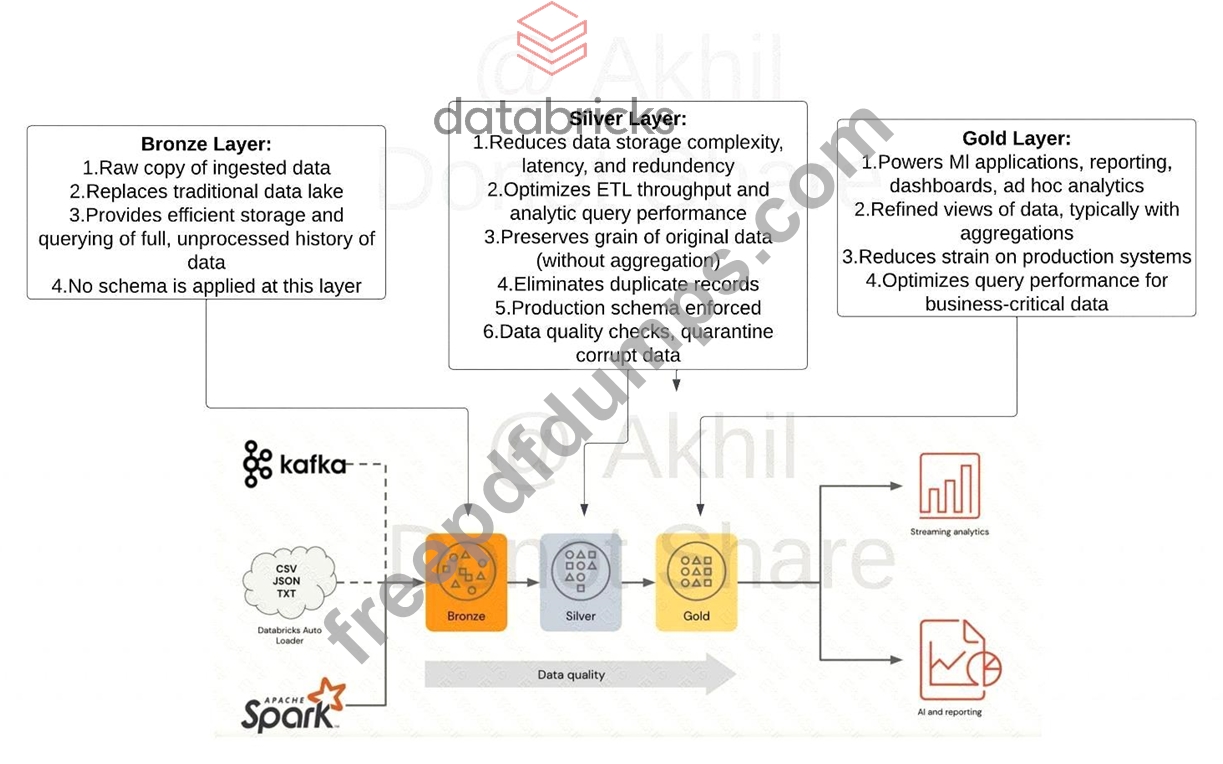
What is the purpose of a gold layer in Multi-hop architecture?