
NCP-AII Exam Question 16
You are monitoring a server with 8 GPUs used for deep learning training. You observe that one of the GPUs reports a significantly lower utilization rate compared to the others, even though the workload is designed to distribute evenly. 'nvidia-smi' reports a persistent "XID 13" error for that GPU. What is the most likely cause?
NCP-AII Exam Question 17
After installing a new NVIDIA GPU in an AI server, you run 'nvidia-smi' and receive the error 'NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.' You have verified the driver is installed. What is the MOST likely cause?
NCP-AII Exam Question 18
Which of the following techniques can be used to optimize storage performance for deep learning training?
NCP-AII Exam Question 19
Consider the following Dockerfile snippet:
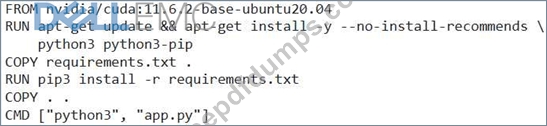
This Dockerfile is used to build a deep learning application. After building and running a container from this image, you observe that the application is not detecting the GPU. You have verified that the NVIDIA Container Toolkit is installed and configured correctly on the host. What is the most likely reason for this issue?
This Dockerfile is used to build a deep learning application. After building and running a container from this image, you observe that the application is not detecting the GPU. You have verified that the NVIDIA Container Toolkit is installed and configured correctly on the host. What is the most likely reason for this issue?
NCP-AII Exam Question 20
You're troubleshooting a DGX-I server exhibiting performance degradation during a large-scale distributed training job. 'nvidia-smu shows all GPUs are detected, but one GPU consistently reports significantly lower utilization than the others. Attempts to reschedule orkloads to that GPU frequently result in CUDA errors. Which of the following is the MOST likely cause and the BEST initial roubleshooting step?