
DP-100 Exam Question 1
You have a binary classifier that predicts positive cases of diabetes within two separate age groups.
The classifier exhibits a high degree of disparity between the age groups.
You need to modify the output of the classifier to maximize its degree of fairness across the age groups and meet the following requirements:
* Eliminate the need to retrain the model on which the classifier is based.
* Minimize the disparity between true positive rates and false positive rates across age groups.
Which algorithm and panty constraint should you use? To answer, select the appropriate options in the answer are a. NOTE: Each correct selection is worth one point.

The classifier exhibits a high degree of disparity between the age groups.
You need to modify the output of the classifier to maximize its degree of fairness across the age groups and meet the following requirements:
* Eliminate the need to retrain the model on which the classifier is based.
* Minimize the disparity between true positive rates and false positive rates across age groups.
Which algorithm and panty constraint should you use? To answer, select the appropriate options in the answer are a. NOTE: Each correct selection is worth one point.

DP-100 Exam Question 2
You train a machine learning model.
You must deploy the model as a real-time inference service for testing. The service requires low CPU utilization and less than 48 MB of RAM. The compute target for the deployed service must initialize automatically while minimizing cost and administrative overhead.
Which compute target should you use?
You must deploy the model as a real-time inference service for testing. The service requires low CPU utilization and less than 48 MB of RAM. The compute target for the deployed service must initialize automatically while minimizing cost and administrative overhead.
Which compute target should you use?
DP-100 Exam Question 3
You plan to create a speech recognition deep learning model.
The model must support the latest version of Python.
You need to recommend a deep learning framework for speech recognition to include in the Data Science Virtual Machine (DSVM).
What should you recommend?
The model must support the latest version of Python.
You need to recommend a deep learning framework for speech recognition to include in the Data Science Virtual Machine (DSVM).
What should you recommend?
DP-100 Exam Question 4
You create an Azure Machine Learning workspace.
You must create a custom role named DataScientist that meets the following requirements:
Role members must not be able to delete the workspace.
Role members must not be able to create, update, or delete compute resource in the workspace.
Role members must not be able to add new users to the workspace.
You need to create a JSON file for the DataScientist role in the Azure Machine Learning workspace.
The custom role must enforce the restrictions specified by the IT Operations team.
Which JSON code segment should you use?
You must create a custom role named DataScientist that meets the following requirements:
Role members must not be able to delete the workspace.
Role members must not be able to create, update, or delete compute resource in the workspace.
Role members must not be able to add new users to the workspace.
You need to create a JSON file for the DataScientist role in the Azure Machine Learning workspace.
The custom role must enforce the restrictions specified by the IT Operations team.
Which JSON code segment should you use?
DP-100 Exam Question 5
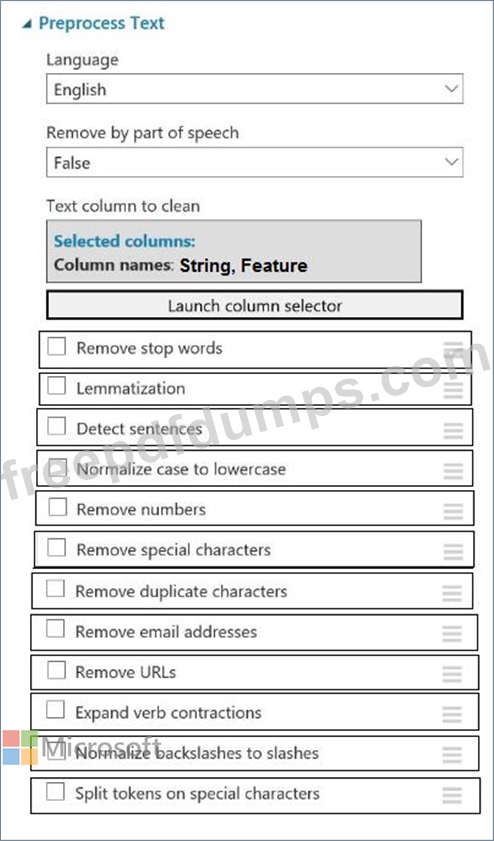
You plan to preprocess text from CSV files. You load the Azure Machine Learning Studio default stop words list.
You need to configure the Preprocess Text module to meet the following requirements:
Ensure that multiple related words from a single canonical form.
Remove pipe characters from text.
Remove words to optimize information retrieval.
Which three options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to configure the Preprocess Text module to meet the following requirements:
Ensure that multiple related words from a single canonical form.
Remove pipe characters from text.
Remove words to optimize information retrieval.
Which three options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
