DP-200 Exam Question 211
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database named DB1 that contains a table named Table1. Table1 has a field named Customer_ID that is varchar(22).
You need to implement masking for the Customer_ID field to meet the following requirements:
* The first two prefix characters must be exposed.
* The last four prefix characters must be exposed.
All other characters must be masked.
Solution: You implement data masking and use a random number function mask.
Does this meet the goal?
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure SQL database named DB1 that contains a table named Table1. Table1 has a field named Customer_ID that is varchar(22).
You need to implement masking for the Customer_ID field to meet the following requirements:
* The first two prefix characters must be exposed.
* The last four prefix characters must be exposed.
All other characters must be masked.
Solution: You implement data masking and use a random number function mask.
Does this meet the goal?
DP-200 Exam Question 212
You need to develop a pipeline for processing data. The pipeline must meet the following requirements:
* Scale up and down resources for cost reduction
* Use an in-memory data processing engine to speed up ETL and machine learning operations.
* Use streaming capabilities
* Provide the ability to code in SQL, Python, Scala, and R
* Integrate workspace collaboration with Git
What should you use?
* Scale up and down resources for cost reduction
* Use an in-memory data processing engine to speed up ETL and machine learning operations.
* Use streaming capabilities
* Provide the ability to code in SQL, Python, Scala, and R
* Integrate workspace collaboration with Git
What should you use?
DP-200 Exam Question 213
You are creating a new notebook in Azure Databricks that will support R as the primary language but will also support Scola and SQL.
Which switch should you use to switch between languages?
Which switch should you use to switch between languages?
DP-200 Exam Question 214
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


DP-200 Exam Question 215
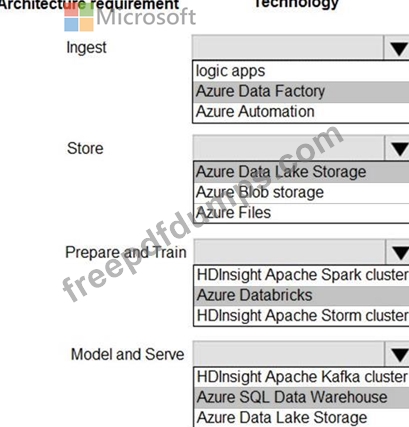
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements.
Ingest:
*Access multiple data sources
*Provide the ability to orchestrate workflow
*Provide the capability to run SQL Server Integration Services packages.
Store:
*Optimize storage for big data workloads.
*Provide encryption of data at rest.
*Operate with no size limits.
Prepare and Train:
*Provide a fully-managed and interactive workspace for exploration and visualization.
*Provide the ability to program in R, SQL, Python, Scala, and Java.
*Provide seamless user authentication with Azure Active Directory.
Model & Serve:
*Implement native columnar storage.
*Support for the SQL language
*Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
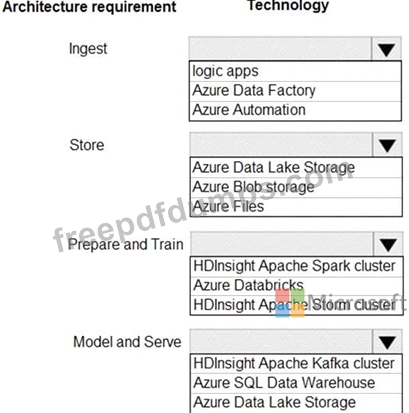
Ingest:
*Access multiple data sources
*Provide the ability to orchestrate workflow
*Provide the capability to run SQL Server Integration Services packages.
Store:
*Optimize storage for big data workloads.
*Provide encryption of data at rest.
*Operate with no size limits.
Prepare and Train:
*Provide a fully-managed and interactive workspace for exploration and visualization.
*Provide the ability to program in R, SQL, Python, Scala, and Java.
*Provide seamless user authentication with Azure Active Directory.
Model & Serve:
*Implement native columnar storage.
*Support for the SQL language
*Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.