
Professional-Machine-Learning-Engineer Exam Question 56
A Data Science team is designing a dataset repository where it will store a large amount of training data commonly used in its machine learning models. As Data Scientists may create an arbitrary number of new datasets every day, the solution has to scale automatically and be cost-effective. Also, it must be possible to explore the data using SQL.
Which storage scheme is MOST adapted to this scenario?
Which storage scheme is MOST adapted to this scenario?
Professional-Machine-Learning-Engineer Exam Question 57
A data scientist wants to use Amazon Forecast to build a forecasting model for inventory demand for a retail company. The company has provided a dataset of historic inventory demand for its products as a .csv file stored in an Amazon S3 bucket. The table below shows a sample of the dataset.

How should the data scientist transform the data?
How should the data scientist transform the data?
Professional-Machine-Learning-Engineer Exam Question 58
You are training a TensorFlow model on a structured data set with 100 billion records stored in several CSV files. You need to improve the input/output execution performance. What should you do?
Professional-Machine-Learning-Engineer Exam Question 59
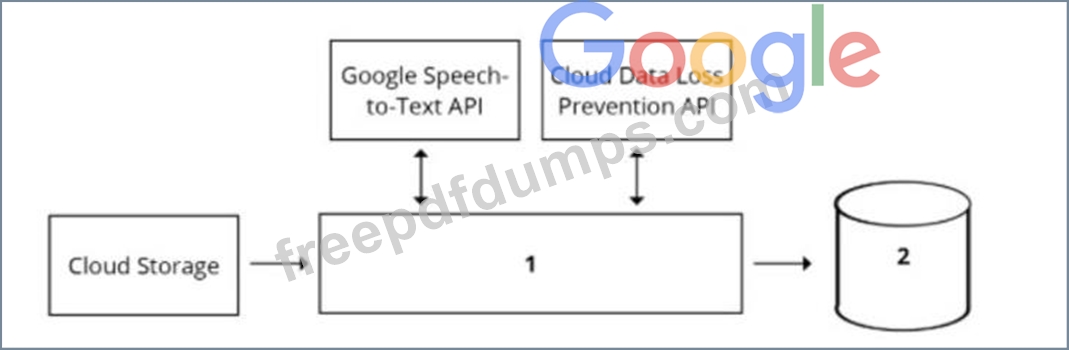
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?
Professional-Machine-Learning-Engineer Exam Question 60
A Marketing Manager at a pet insurance company plans to launch a targeted marketing campaign on social media to acquire new customers. Currently, the company has the following data in Amazon Aurora:
* Profiles for all past and existing customers
* Profiles for all past and existing insured pets
* Policy-level information
* Premiums received
* Claims paid
What steps should be taken to implement a machine learning model to identify potential new customers on social media?
* Profiles for all past and existing customers
* Profiles for all past and existing insured pets
* Policy-level information
* Premiums received
* Claims paid
What steps should be taken to implement a machine learning model to identify potential new customers on social media?