
Professional-Machine-Learning-Engineer Exam Question 36
A monitoring service generates 1 TB of scale metrics record data every minute. A Research team performs queries on this data using Amazon Athena. The queries run slowly due to the large volume of data, and the team requires better performance.
How should the records be stored in Amazon S3 to improve query performance?
How should the records be stored in Amazon S3 to improve query performance?
Professional-Machine-Learning-Engineer Exam Question 37
You work for an online travel agency that also sells advertising placements on its website to other companies.
You have been asked to predict the most relevant web banner that a user should see next. Security is important to your company. The model latency requirements are 300ms@p99, the inventory is thousands of web banners, and your exploratory analysis has shown that navigation context is a good predictor.
You want to Implement the simplest solution. How should you configure the prediction pipeline?
You have been asked to predict the most relevant web banner that a user should see next. Security is important to your company. The model latency requirements are 300ms@p99, the inventory is thousands of web banners, and your exploratory analysis has shown that navigation context is a good predictor.
You want to Implement the simplest solution. How should you configure the prediction pipeline?
Professional-Machine-Learning-Engineer Exam Question 38
Machine Learning Specialist is training a model to identify the make and model of vehicles in images. The Specialist wants to use transfer learning and an existing model trained on images of general objects. The Specialist collated a large custom dataset of pictures containing different vehicle makes and models.
What should the Specialist do to initialize the model to re-train it with the custom data?
What should the Specialist do to initialize the model to re-train it with the custom data?
Professional-Machine-Learning-Engineer Exam Question 39
A machine learning specialist is running an Amazon SageMaker endpoint using the built-in object detection algorithm on a P3 instance for real-time predictions in a company's production application. When evaluating the model's resource utilization, the specialist notices that the model is using only a fraction of the GPU.
Which architecture changes would ensure that provisioned resources are being utilized effectively?
Which architecture changes would ensure that provisioned resources are being utilized effectively?
Professional-Machine-Learning-Engineer Exam Question 40
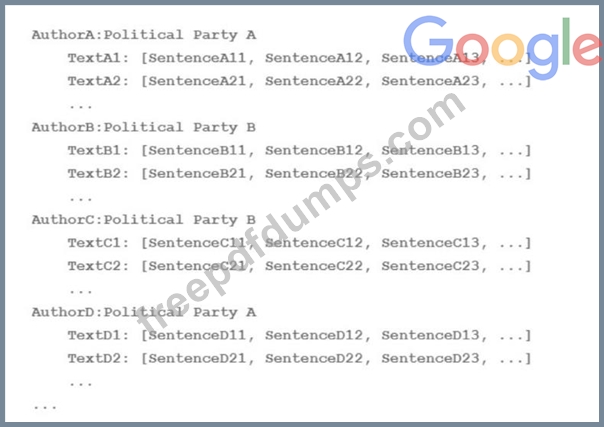
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this:
A)

B)

C)

D)

A)
B)
C)
D)