
Professional-Machine-Learning-Engineer Exam Question 11
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers
Choose 2 answers
Professional-Machine-Learning-Engineer Exam Question 12
Your team needs to build a model that predicts whether images contain a driver's license, passport, or credit card. The data engineering team already built the pipeline and generated a dataset composed of 10,000 images with driver's licenses, 1,000 images with passports, and 1,000 images with credit cards. You now have to train a model with the following label map: ['driversjicense', 'passport', 'credit_card']. Which loss function should you use?
Professional-Machine-Learning-Engineer Exam Question 13
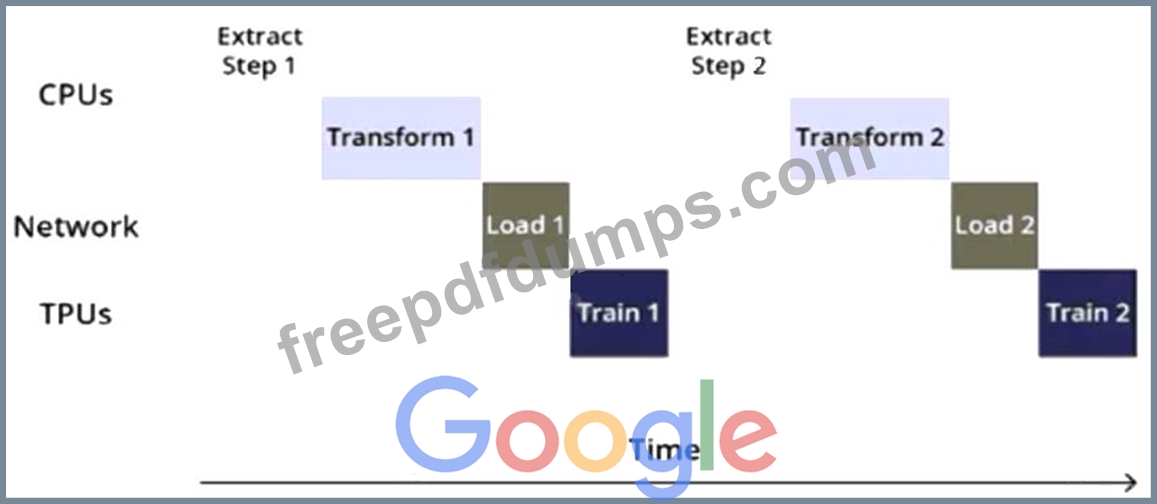
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?
Professional-Machine-Learning-Engineer Exam Question 14
You are training an LSTM-based model on Al Platform to summarize text using the following job submission script:

You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
Professional-Machine-Learning-Engineer Exam Question 15
You are building a linear regression model on BigQuery ML to predict a customer's likelihood of purchasing your company's products. Your model uses a city name variable as a key predictive component. In order to train and serve the model, your data must be organized in columns. You want to prepare your data using the least amount of coding while maintaining the predictable variables. What should you do?