
Professional-Machine-Learning-Engineer Exam Question 16
You work on the data science team for a multinational beverage company. You need to develop an ML model to predict the company's profitability for a new line of naturally flavored bottled waters in different locations. You are provided with historical data that includes product types, product sales volumes, expenses, and profits for all regions. What should you use as the input and output for your model?
Professional-Machine-Learning-Engineer Exam Question 17
You have successfully deployed to production a large and complex TensorFlow model trained on tabular dat a. You want to predict the lifetime value (LTV) field for each subscription stored in the BigQuery table named subscription. subscriptionPurchase in the project named my-fortune500-company-project.
You have organized all your training code, from preprocessing data from the BigQuery table up to deploying the validated model to the Vertex AI endpoint, into a TensorFlow Extended (TFX) pipeline. You want to prevent prediction drift, i.e., a situation when a feature data distribution in production changes significantly over time. What should you do?
You have organized all your training code, from preprocessing data from the BigQuery table up to deploying the validated model to the Vertex AI endpoint, into a TensorFlow Extended (TFX) pipeline. You want to prevent prediction drift, i.e., a situation when a feature data distribution in production changes significantly over time. What should you do?
Professional-Machine-Learning-Engineer Exam Question 18
You have been asked to build a model using a dataset that is stored in a medium-sized (~10 GB) BigQuery table. You need to quickly determine whether this data is suitable for model development. You want to create a one-time report that includes both informative visualizations of data distributions and more sophisticated statistical analyses to share with other ML engineers on your team. You require maximum flexibility to create your report. What should you do?
Professional-Machine-Learning-Engineer Exam Question 19
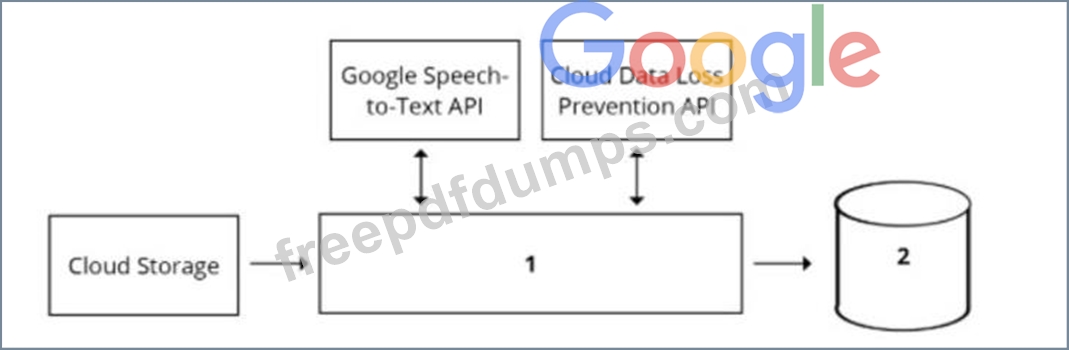
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?
Professional-Machine-Learning-Engineer Exam Question 20
You work for a social media company. You need to detect whether posted images contain cars. Each training example is a member of exactly one class. You have trained an object detection neural network and deployed the model version to Al Platform Prediction for evaluation. Before deployment, you created an evaluation job and attached it to the Al Platform Prediction model version. You notice that the precision is lower than your business requirements allow. How should you adjust the model's final layer softmax threshold to increase precision?
Premium Bundle
Newest Professional-Machine-Learning-Engineer Exam PDF Dumps shared by Actual4test.com for Helping Passing Professional-Machine-Learning-Engineer Exam! Actual4test.com now offer the updated Professional-Machine-Learning-Engineer exam dumps, the Actual4test.com Professional-Machine-Learning-Engineer exam questions have been updated and answers have been corrected get the latest Actual4test.com Professional-Machine-Learning-Engineer pdf dumps with Exam Engine here:
(300 Q&As Dumps, 30%OFF Special Discount: Freepdfdumps)