
DP-200 Exam Question 101
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is less than 1 MB.
Does this meet the goal?
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values. 75% of the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is less than 1 MB.
Does this meet the goal?
DP-200 Exam Question 102
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at test layer must meet the following requirements:
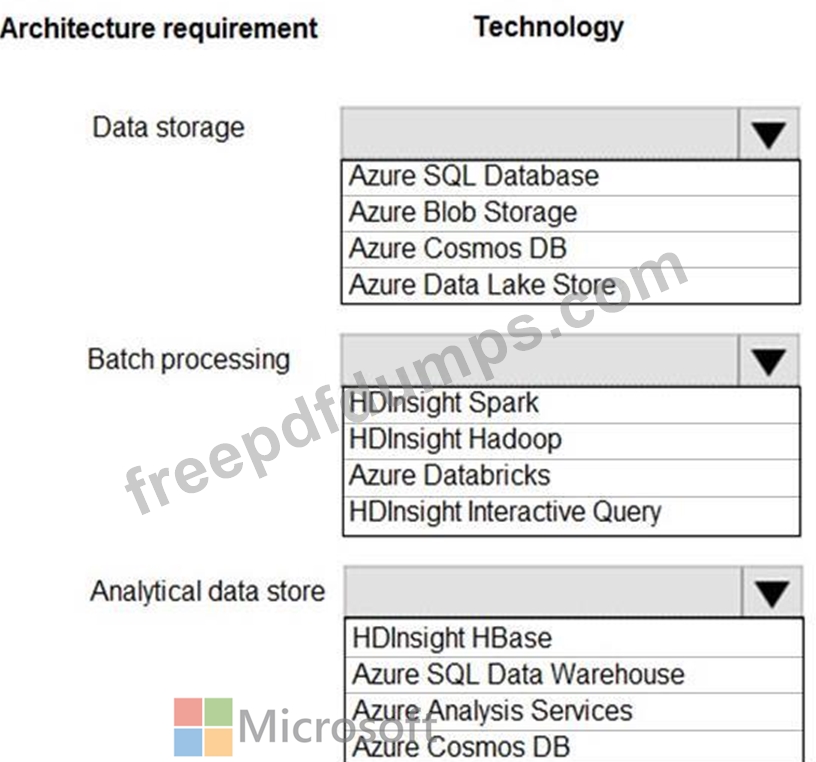
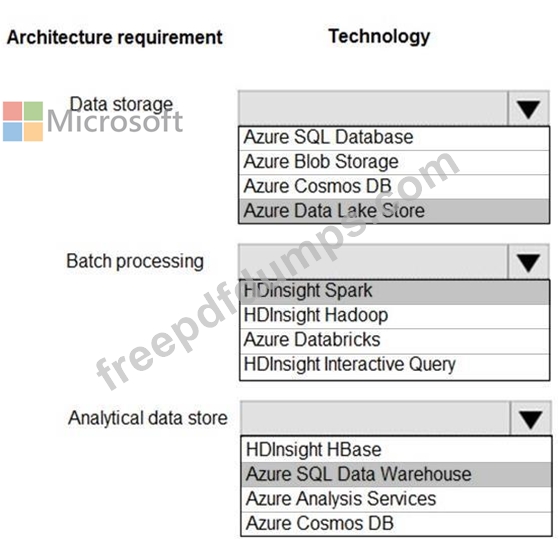
Data storage:
*Serve as a repository (or high volumes of large files in various formats.
*Implement optimized storage for big data analytics workloads.
*Ensure that data can be organized using a hierarchical structure.
Batch processing:
*Use a managed solution for in-memory computation processing.
*Natively support Scala, Python, and R programming languages.
*Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
*Support parallel processing.
*Use columnar storage.
*Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use? To answer, select the appropriate options in the answer area NOTE: Each correct selection is worth one point.
The data at test layer must meet the following requirements:
Data storage:
*Serve as a repository (or high volumes of large files in various formats.
*Implement optimized storage for big data analytics workloads.
*Ensure that data can be organized using a hierarchical structure.
Batch processing:
*Use a managed solution for in-memory computation processing.
*Natively support Scala, Python, and R programming languages.
*Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
*Support parallel processing.
*Use columnar storage.
*Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use? To answer, select the appropriate options in the answer area NOTE: Each correct selection is worth one point.
DP-200 Exam Question 103
Note: This question is part of series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Create a remote service binding pointing to the Azure Data Lake Gen 2 storage account
2. Create an external file format and external table using the external data source
3. Load the data using the CREATE TABLE AS SELECTstatement
Does the solution meet the goal?
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Create a remote service binding pointing to the Azure Data Lake Gen 2 storage account
2. Create an external file format and external table using the external data source
3. Load the data using the CREATE TABLE AS SELECTstatement
Does the solution meet the goal?
DP-200 Exam Question 104
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.

The partition key is set to the OrderId attribute.
Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete.
You need to reduce the amount of time it takes to execute the problematic queries.
Solution: You create a lookup collection that uses ProductName as a partition key and OrderId as a value.
Does this meet the goal?
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.
The partition key is set to the OrderId attribute.
Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete.
You need to reduce the amount of time it takes to execute the problematic queries.
Solution: You create a lookup collection that uses ProductName as a partition key and OrderId as a value.
Does this meet the goal?
DP-200 Exam Question 105
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Create an external data source pointing to the Azure storage account
2. Create a workload group using the Azure storage account name as the pool name
3. Load the data using the INSERT...SELECTstatement
Does the solution meet the goal?
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Create an external data source pointing to the Azure storage account
2. Create a workload group using the Azure storage account name as the pool name
3. Load the data using the INSERT...SELECTstatement
Does the solution meet the goal?