
DP-200 Exam Question 196
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one query, and two outputs.
Does this meet the goal?
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one query, and two outputs.
Does this meet the goal?
DP-200 Exam Question 197
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior.
You need to implement logging.
Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account.
Does the solution meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company uses Azure Data Lake Gen 1 Storage to store big data related to consumer behavior.
You need to implement logging.
Solution: Configure Azure Data Lake Storage diagnostics to store logs and metrics in a storage account.
Does the solution meet the goal?
DP-200 Exam Question 198
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.

The partition key is set to the OrderId attribute.
Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete.
You need to reduce the amount of time it takes to execute the problematic queries.
Solution: You change the partition key to include ProductName.
Does this meet the goal?
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named Sales in an Azure Cosmos DB database. Sales has 120 GB of data. Each entry in Sales has the following structure.
The partition key is set to the OrderId attribute.
Users report that when they perform queries that retrieve data by ProductName, the queries take longer than expected to complete.
You need to reduce the amount of time it takes to execute the problematic queries.
Solution: You change the partition key to include ProductName.
Does this meet the goal?
DP-200 Exam Question 199
You have a new Azure Data Factory environment.
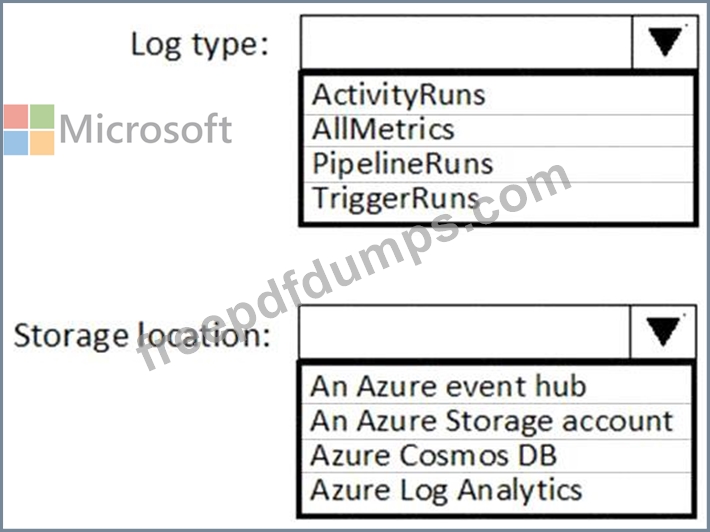
You need to periodically analyze pipeline executions from the last 60 days to identify trends in execution durations. The solution must use Azure Log Analytics to query the data and create charts.
Which diagnostic settings should you configure in Data Factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to periodically analyze pipeline executions from the last 60 days to identify trends in execution durations. The solution must use Azure Log Analytics to query the data and create charts.
Which diagnostic settings should you configure in Data Factory? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

DP-200 Exam Question 200
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one reference input, two queries, and four outputs.
Does this meet the goal?
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are developing a solution that will use Azure Stream Analytics. The solution will accept an Azure Blob storage file named Customers. The file will contain both in-store and online customer details. The online customers will provide a mailing address.
You have a file in Blob storage named LocationIncomes that contains median incomes based on location. The file rarely changes.
You need to use an address to look up a median income based on location. You must output the data to Azure SQL Database for immediate use and to Azure Data Lake Storage Gen2 for long-term retention.
Solution: You implement a Stream Analytics job that has one streaming input, one reference input, two queries, and four outputs.
Does this meet the goal?