
NCM-MCI-5.15 Exam Question 11
Refer to the exhibit.
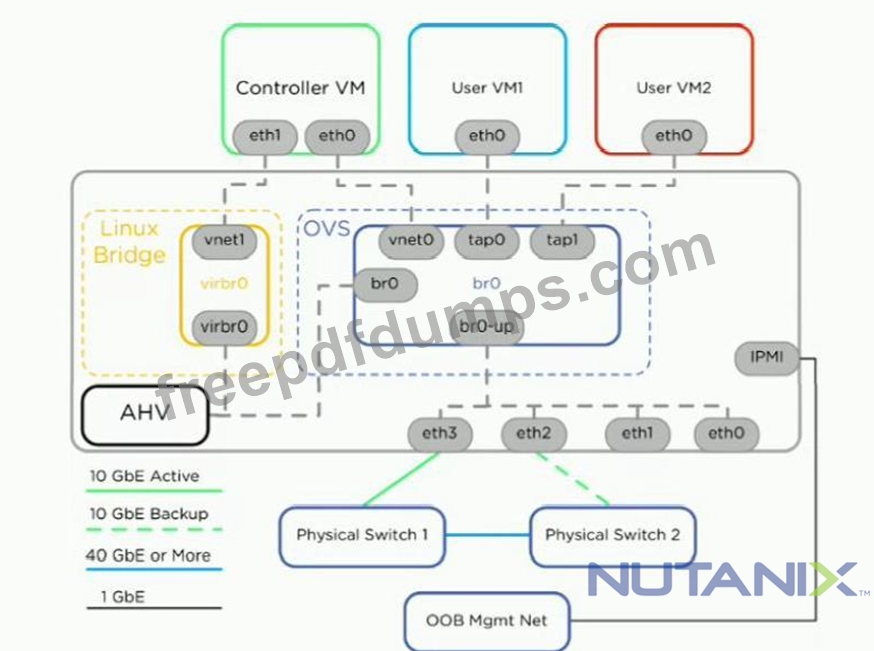
A Nutanix host is connected as shown in the exhibit with br0-up set to active/backup. Physical Switch 1 experiences a power outage causing br0-up to failover to using eth2. The CVM and host become inaccessible.
User VMs restart on other hosts in the cluster, which causes a disruption to those VMs.
Which configuration issue likely caused this outage?
A Nutanix host is connected as shown in the exhibit with br0-up set to active/backup. Physical Switch 1 experiences a power outage causing br0-up to failover to using eth2. The CVM and host become inaccessible.
User VMs restart on other hosts in the cluster, which causes a disruption to those VMs.
Which configuration issue likely caused this outage?
NCM-MCI-5.15 Exam Question 12
An administrator has a VM that consumes large amounts of storage and has the following characteristics:
* Create large / sequential writes
* Data must be kept for years
* Data is normally only accessed at the end of the year to run report
The administrator decides to use Erasure Coding to save space.
Which feature should the administrator utilize to save space for this VM?
* Create large / sequential writes
* Data must be kept for years
* Data is normally only accessed at the end of the year to run report
The administrator decides to use Erasure Coding to save space.
Which feature should the administrator utilize to save space for this VM?
NCM-MCI-5.15 Exam Question 13
The networking team makes changes to the Top of Rack switches to which the Nutanix cluster are attached. A few VMs are able to communicate with each other on the same node but are unable to connect to other parts of the network.
What is the likely cause of this issue?
What is the likely cause of this issue?
NCM-MCI-5.15 Exam Question 14
An administrator needs to make sure an RF2 cluster can survive a complete rack failure without negatively effecting workload performance. The current cluster configuration consists of the following:
* 30 nodes: distributed 10 nodes per rack across three 42U rack
* Each nodes is configured with 40TB usable storage all flash (Cluster Total 1.2 PB Usable)
* Current cluster utilization is 900TB storage
Which configuration changes should be made to make sure that the cluster meets the requirements?
* 30 nodes: distributed 10 nodes per rack across three 42U rack
* Each nodes is configured with 40TB usable storage all flash (Cluster Total 1.2 PB Usable)
* Current cluster utilization is 900TB storage
Which configuration changes should be made to make sure that the cluster meets the requirements?
NCM-MCI-5.15 Exam Question 15
An administrator is supporting a business critical environment and deploys metro availability to achieve a zero data loss configuration. The two clusters are connected by a 1GbE connection. A new workload is going to be deployed to this cluster. This workload requires a sustained 150MB/S of write throughput and 20MB/s of read throughput.
Which change must be made to deploy the workload successfully on this cluster?
Which change must be made to deploy the workload successfully on this cluster?
